

If you have read my previous blog, “Go Beyond CSV: Data Ingestion with Pandas,” then you might have guessed how we can scrape HTML tables from any website without BeautifulSoup, Selenium, Scrapy, or any other web scraping tools.
If you are a beginner trying to learn web scraping or an expert, I bet setting up libraries, creating soup, and writing XPath or CSS Selectors is tedious. When you are short on time, it’s difficult to check the source code and inspect each HTML code.
No more worries. If you are familiar with the pandas read_X() method, then web scraping HTML tables is far easier. All you need is patience to work with your initial result to get the desired output.
In most websites (unless the data table is loaded with JavaScript), the table data is kept inside the HTML table tag, <table></table>.
The pandas read_X() method is popularly known as the data ingestion method. read_csv(), read_excel(), read_sql_query(), read_json(), and many other methods are available. Here, we are interested in read_html().
Let’s Start
To get a sense of how you can scrape data using pandas read_html(), you will work with two websites. Wikipedia and the Cryptocurrency Prices table by CoinMarketCap.
First, you will extract a table from the Grammy Award records from the following URL: https://en.wikipedia.org/wiki/Grammy_Award_records at Wikipedia.
Most Grammys won

To scrape the table of most Grammy wins, you will import the pandas library and use the read_html() method with the URL of Wikipedia. To extract the first table, you will use [0] at the end of the read_html() method. Once that is done, you will simply print the obtained data.
#import the Pandas library
import pandas as pd#scrap 1st table data and store as dataframe name df_award1
df_award1 =pd.read_html('https://en.wikipedia.org/wiki/Grammy_Award_records') [0]#view the dataset as pandas dataframe object
df_award1.head()
Output:


Here, you scraped the first table of Most Grammys won awards. To scrap the next table, all you need to change is the number between the square brackets []. To get the table of the most Grammys won by a female artist, you need to add [1].
Output:


Scraping Cryptocurrency Prices
Now, let’s try a different website. You will scrap the cryptocurrency market values from CoinMarketCap.
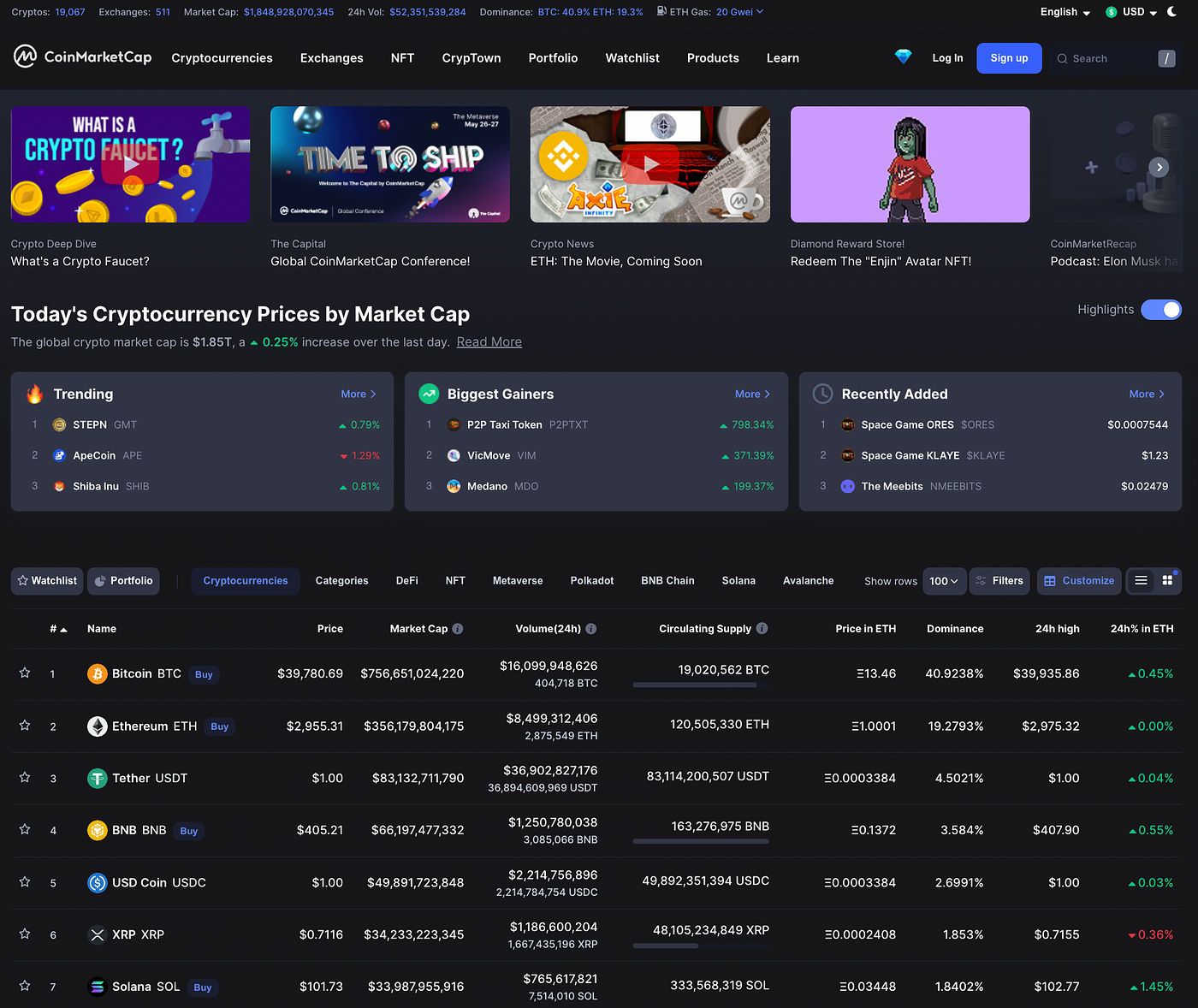
As you can see here, there are a few tables called “Trending,” “Biggest Gainers,” “Recently Added,” and the main Cryptocurrency Price table. You will scrap this big table. The code is the same. All you need to work out is to maintain the values between the square brackets [].
#import the Pandas library
import pandas as pd#scrap 1st table data and store as dataframe name df_crypto
df_crypto = pd.read_html('https://coinmarketcap.com/')[0]#view the dataset as pandas dataframe object
df_crypto.head()
Output:

Here, if you see, you have all the data, but some columns still show NaN (null values). If you see, there is an unnamed column that is not of any use. Whatsoever, you have your data scraped without using BeautifulSoup, Selenium, Scrapy, or any scraping tool. But here, you need a lot of time to clean the data.
Give the following blog a read if you want to understand how to discover and visualize missing data:
Remember that, while this blog focuses on web scraping without the use of scraping tools, I am not opposed to them. They help you save a great deal of time. You won’t have to worry about data cleansing if you utilize a scraping tool. You can extract data in a more orderly and organized manner.
So, if you have read this far, I’m guessing you have learned how to scrape HTML tables from any website using Panda’s read_html() method.
